3년 전에 만들었던 SMS Forward에 이어 최근에 만든 조잡 어플리케이션 2호 Android SMS Tethering Swich Application 이다.
지난 3년간 SMS Forward Application으로 업무폰의 데이터를 개인폰으로 선물하면서 아무런 불편없이 모바일 라이프를 잘 하던 중 어느날 한계점이 찾아왔다. 데이터 선물하기로 개인폰에 보낼 수 있는 데이터는 2기가가 한계인데(SKT 이거 좀 늘려랏!) 어느순간 지하철에서 페북과 유투브 동영상을 자주 보게 되면서 2기가로는 택도 없는 상태가 되었기 때문이다. 그래서 생각난 것이 업무폰을 테더링 머신으로 들고다니면 어떨까? 하는 것이었다.
처음은 뭐 괜찮은듯 했지만 곧바로 새로운 장애물에 부딪혔는데 3년이나 된 업무폰이 배터리가 거의 다 맛이 가서 골골댄다는 것이다. 테더링 2시간이면 폰이 꺼졌다. 업무용 폰을 새로 지급 받을까 했지만 제대로 쓰지도 않을 비싼 폰을 새로 받기는 좀 찜찜하기도 해서 이러지도 저러지도 못하고 있다가 마침 안드로이드 개발자인 나에게 테스트용 새 폰이 지급되었다. 그래서 다음과 같은 뻘짓을 해봤는데
1. 업무폰으로 데이터 쉐어링 서비스 신청해서 데이터 전용 USIM을 발급 받는다. 이 데이터 전용 USIM은 전화 발신, SMS 발신 기능이 제한된다.
2. 개발자 테스트용 폰에 데이터 전용 USIM을 장착한다.
3. 이제 배터리가 빵빵한 개발자 테스트용 폰을 테더링 머신으로 들고다닌다.
제법 괜찮았다. 다만 한가지 불편함이 있는데 아무리 배터리 빵빵한 신형폰도 테더링을 켜놓음녀 10시간도 버티기 어렵다는 것이다. 그래서 테더링 폰을 가방에 넣고 다니면서 필요할때만 테더링을 껏다 켰다 했어야 했는데 이거 은근 불편하고 잠깐만 아차하면 배터리 광탈 당하는 상황을 면치 못했다.
그러다 한가지 재미있는 사실을 알게 되었는데 데이터 전용 USIM도 SMS 수신은 된다는 것이다. 그래서 생각해본게 SMS Foward 비슷하게 SMS로 테더링을 on/off 시키는 앱을 만들어 보는 것이었다. 테더링 on/off 메소드가 public으로 제공되지 않아 난감했지만 우리에게 역시 구글신이 계시다. 여기저기 구글링하니 곧바로 방법이 나오더라. 결국 Java reflection으로 WifiService 객체에 숨겨진 테더링 제어 메소드를 찾아 돌리는 방법밖에 없더라.
여튼 만들고 나니 잘 동작했다. 만든 시점부터 현재까지 SMS로 개발폰의 테더링을 on/off 하고 있는데 확실히 이전보다 불편함이 줄었다. 무엇보다 SKT가 데이터 요금 강화하려는 의도인지 전화/SMS가 무료인 요금제를 내놓아서 문제비용 걱정도 없어졌다.
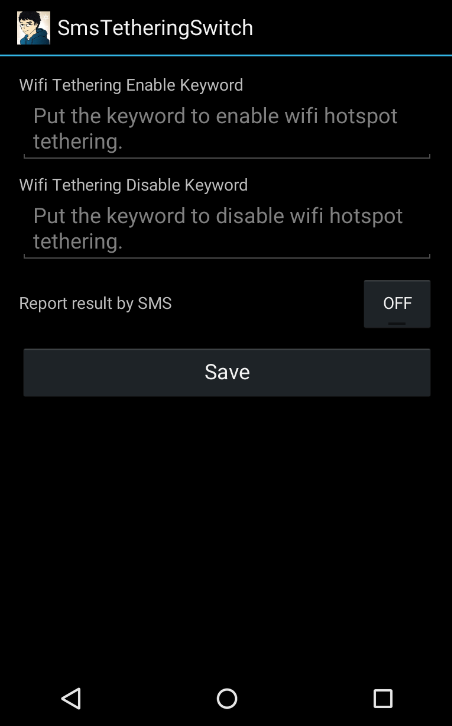
UI는 SMS Forward보단 좀 복잡해졌다. 일단 SMS로 테더링을 켜는 문자열과 SMS로 테더링을 끄는 문자열을 입력하면 그걸 기준으로 SMS를 필터링 해서 테더링을 on/off한다. 그리고 테더링 제어 결과를 SMS로 알려주는 기능도 넣긴 했는데 안타깝게도 개발에 사용한 데이터 쉐어 USIM이 문자 발송 제한이 걸려있어 제대로 작동하는지 테스트 해보진 못했다.
하루 정도 테스트후 개발폰의 SMS를 열어보면 무슨 정신 분열자가 같은 느낌이 난다. 좌측이 테더링 머신, 우측이 개인폰이다. 테더링 머신의 테더링 결과 문자발송 실패 아이콘을 보면 뭔가 가슴아프다.
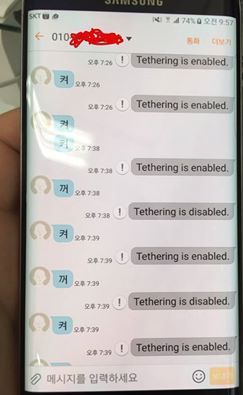
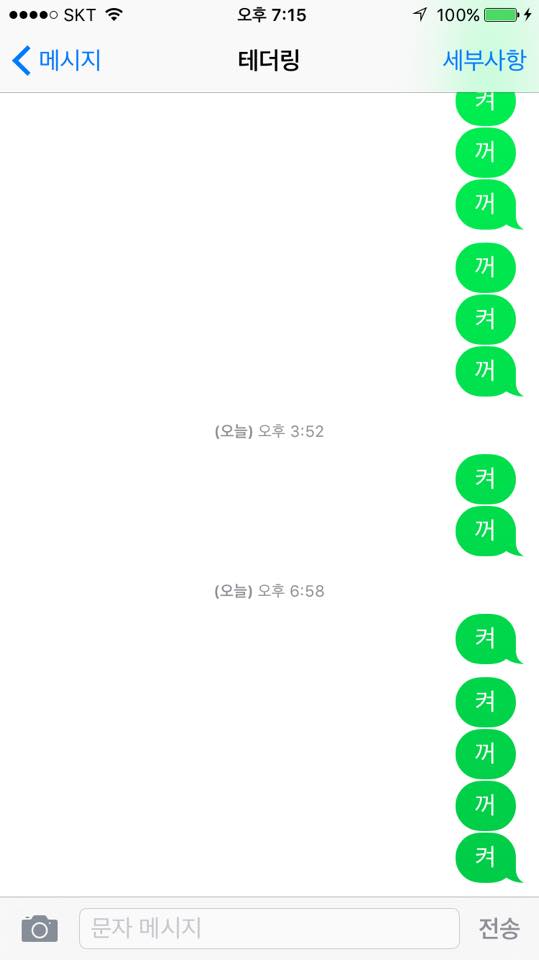
현재까지 불편없이 잘 쓰고 있다. 다만 SMS로 ‘꺼’ 날리는 거 조차 잊어서 종종 방전된 개발폰을 보아야 하는 문제점이 있는데 이건 해결이 불가능 하다. 테더링 켜지고 2시간 뒤 자동으로 꺼지는 기능이라도 추가해야 하나?
github link : https://github.com/abh0518/sms_tethering_switch



![app - AndroidBuildSetting - [~:AndroidStudioProjects:AndroidBuildSetting] 2016-06-09 10-35-32](http://abh0518.net/tok/wp-content/uploads/2016/06/app-AndroidBuildSetting-AndroidStudioProjectsAndroidBuildSetting-2016-06-09-10-35-32.png)
![activity_main.xml - sms_tethering_switch - [~:AndroidStudioProjects:sms_tethering_switch] 2016-06-03 13-52-21](http://abh0518.net/tok/wp-content/uploads/2016/06/activity_main.xml-sms_tethering_switch-AndroidStudioProjectssms_tethering_switch-2016-06-03-13-52-21.png)